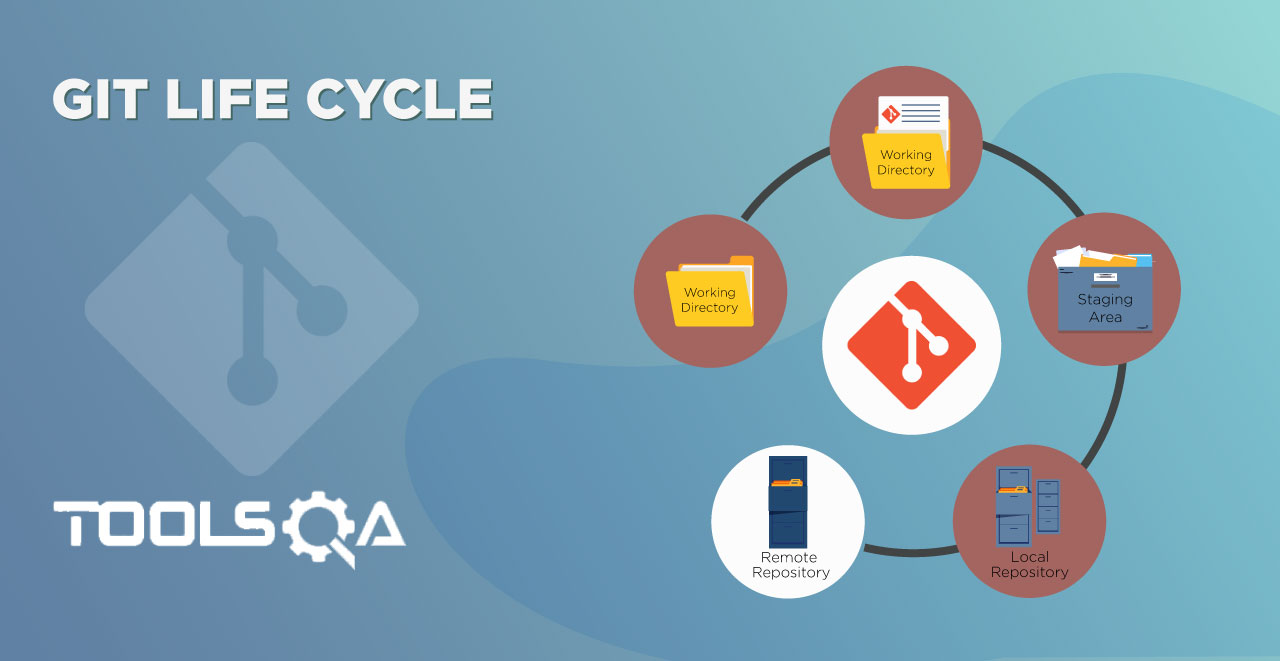
In the series of tutorials up to now, we've seen the introductory concepts of Git. In this tutorial we will be focusing on different git terminologies of git which will help us in the further tutorials on this course.
Before we begin, let's consider the background setup indicated by the following image explained step-by-step in the following section.
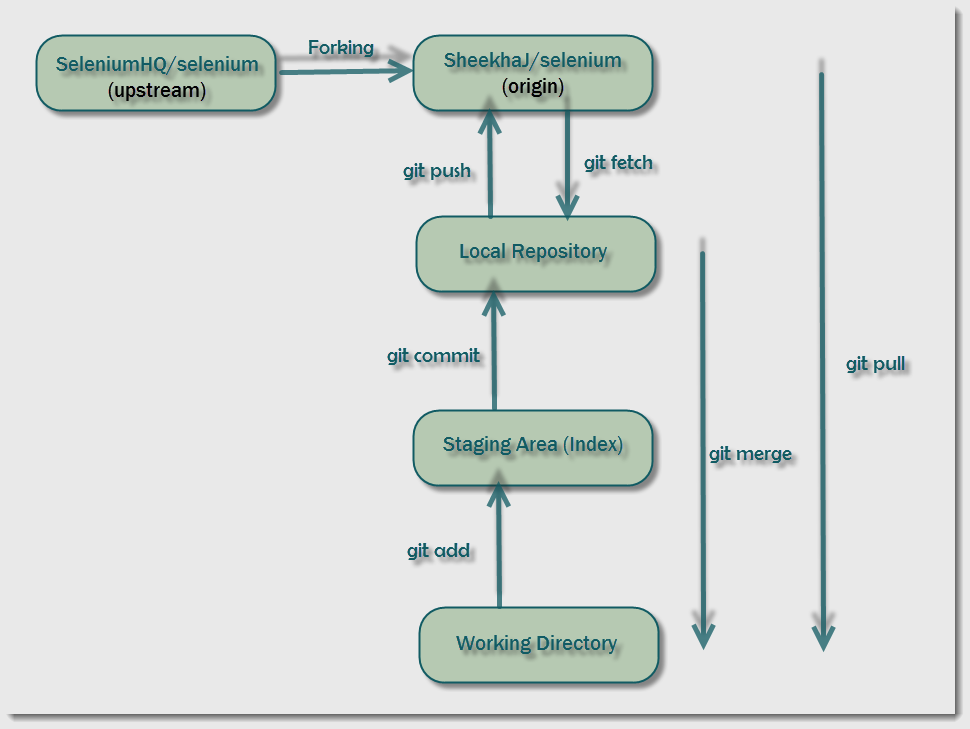
1. Consider that we're working on a feature to be added to the Selenium source-code. Since it's an open-source project, anyone can contribute to the project. The source code for Selenium is hosted at https://github.com/SeleniumHQ/selenium.git .
2. To begin contributing to this project, we need to get the source code in our local machine (Distributed Structure, if you recall). This is done by forking the Selenium repository and checking out the forked repository. This will create a clone of the original repository in our local machine. We will develop our new feature in this working directory.
3. To keep track of the changes that we make in our working directory, we'll commit them to our local repository.
4. To have the flexibility of resuming work on the new feature from any machine, we'll push the changes from the local repository to our forked repository. That is, we're not yet ready to publish the changes to the Selenium community but still want our changes to be recorded in Github. For this, we'll push the changes to the forked repository.
5. Once we're ready to roll our feature, changes on our branch in the forked repository have to be merged with the original Selenium repository.
Let's begin understanding various Git terminologies based on this setup.
Common Git Terminologies
Repository
Repositories can be imagined similar to the folders in your system. A repository in Github contains all the project's files including the documentation and all the revisions done on this project. It is the most basic element of Github.
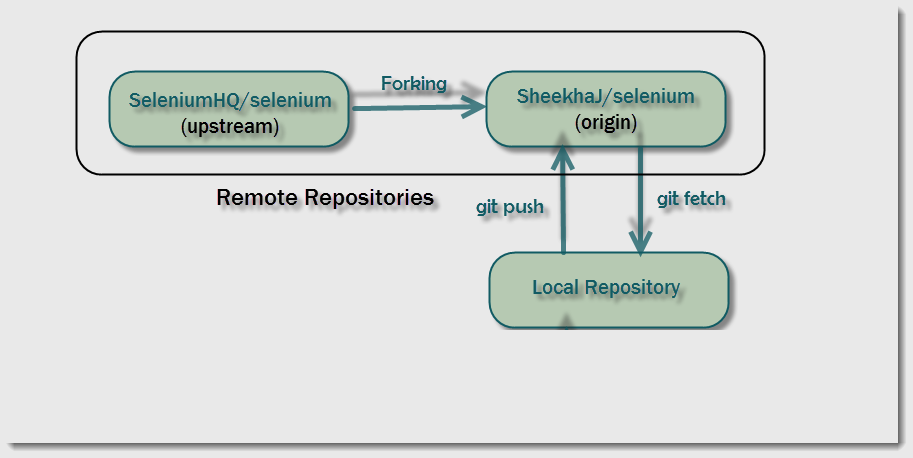
Remote
Remote is the term used to refer to the repository hosted in Github. A developer's or company's local Git repository hosted in Github or any other Git host platform (Bitbucket, GitKraken, etc) for sharing and collaboration is generally called Remote repository.
The Selenium repository seen in my Github account is called a remote repository. It's simply a clone of your local repository in the cloud-hosted by Github.
Note that remote is a generic term used to refer to a repository in Github. In other words, the remote can be used to refer to your origin as well as upstream. Don't worry, if this statement doesn't make sense right now. This will be elaborated once the terms origin and upstream are explained.
Branch
Branch represents a line of development in the repository (be it local or remote repository). In other words, a series of commits of a particular project indicates a branch.A repository can have multiple branches.
It's important to note here that repositories are just a stand-alone concept of a project. They get their meaning from the code on their branches. The branch could be the one where there are commits for all the stable features; another branch for commits related to functionalities in the upcoming release; another branch for commits related to bug-fixes and so on.
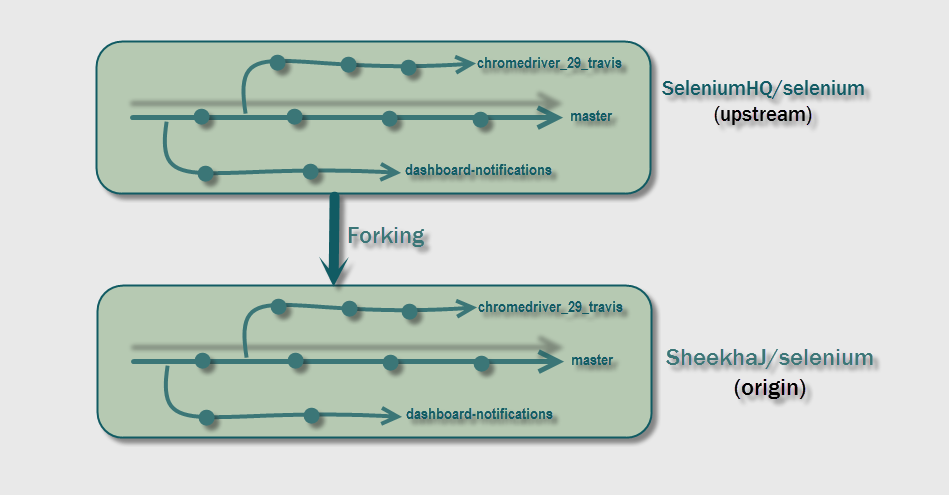
As seen in the image above, the Selenium repository has multiple branches named master, chromedriver_29_travis, dashboard-notifications, etc.
Branches help you use popular workflows like Git Branching workflow and Git-Flow workflow. You can read more about Git Lifecycle in the next tutorial.
Master
Master is the default name of a repository's active development branch. Unless explicitly specified otherwise, all Git operations are performed with respect to code on this default branch.
As seen in our example, the master is the name of the default branch on which the Selenium repository code is present. Whenever we clone a repository, all the branches present in the repository at the time will be cloned as it is.
Commit
The commit command is used to save the changes to your local repository. State of files at a given point of time in repository's history is referred by a commit. In Git, it's not like an autosave. For example, in Google docs, you make the changes and those are saved automatically. This does not happen in Git. You need to explicitly execute the commit command in order to save the changes to your local repository.
It must be remembered that commit does not automatically sync your committed changes to the remote server. For that, you need to execute push, pull commands which we will later talk about.
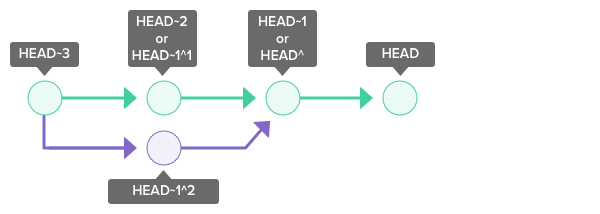
Head
The topmost commit on a branch of a repository is termed as the HEAD. That is, irrespective of the state of the repository, its most recent commit is called the Head. When a new commit is made to the repository, this new commit becomes the head. Note that this term is also used with respect to a particular checked-out branch.
Checkout
The process of downloading code from remote repository is called Checkout. In other words, when a remote Git repository is cloned to a local machine, it's termed as checkout of code.
This term is used in terms of a particular branch. When any branch is not explicitly specified, the code on the default branch (usually called the master branch) is checked-out. But even when you download code from any other branch, it's termed as checkout of that particular branch. You can checkout any desired status of the repository which may include master, developer etc.
Index
An index is the cache area between the working directory and the local git repository.
With reference to our setup, consider a group of files where variables have been refactored. As noted in the tutorial on Git Life-cycle, there are two stages to committing this group of files:
-
Add the files to the staging area by using the git add
<fileName>command. -
Commit the files to the local Git repository by using the git commit
<fileName>command.
Thus index is nothing but the state of files after step 1. That is, the index is simply a view that shows the files that will constitute the new commit. The advantage of having the index is that it allows you to group a list of related modified files that are to be logically committed together. In other words, out of a bunch of files that are modified in the working directory, one can selectively group files in the index and then commit them with an appropriate commit message. In the absence of an index, all the modified files from the working directory would have to be committed at once without being able to distinguish small progressive changes. It is also noteworthy that the term used in the Introduction to Git tutorial, the stage area is also called index.
Push
The process of uploading the recorded changes (commits) from local Git repository to the remote Git repository is called pushing. After the changes from the working directory have been committed to the local repository, these changes have to be pushed to the remote repository as well. In the case of a team, this exercise helps the team view the changes made by other developers to the repository and work on them. Refer to the tutorial on Git Push
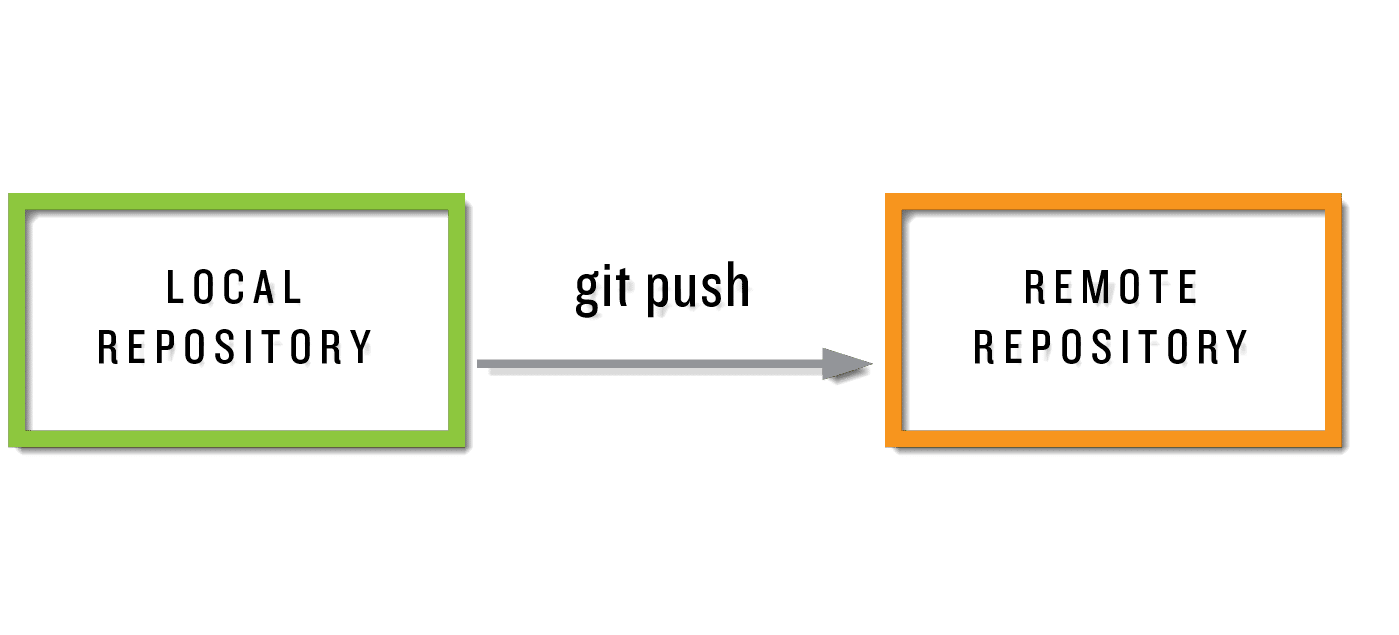 Note that pushing is not an automatic process and has to be performed manually every time. First, you commit the changes to the local Git repository and then push them to the remote repository.
Note that pushing is not an automatic process and has to be performed manually every time. First, you commit the changes to the local Git repository and then push them to the remote repository.
Fetch
Downloading code and commit history from remote Git to local Git repository is known as fetching. Changes are continually made to the Selenium repository from which our code has been derived. It's important to regularly update our code with the latest changes made to the original repository. This process of getting the changes (that is commit history and the actual code) is called fetching. Refer to the tutorial on Git Fetch & Merge.
However, it's important to note here that fetching doesn't change the state of code in the local working directory. That is, only when the fetched code is merged with the local code does its state change. Let's understand this process in greater detail in the tutorial on the Git branching model.
Merge
Merge operation is used to combine multiple commits into one single history. While developing code, you commit your changes on top of the repository's history after checkout. Meanwhile, commits are added by other team members on the same branch in remote repository. This causes the histories of both - a local copy of a remote branch (also known as a remote-tracking branch) and the remote branch to diverge. To push your local commits to the remote repository commits from remote repository have to be fetched and then merged in the working directory. Once we have a coherent history in our working directory, it can be pushed to the remote.
Due to such a nature of the merge operation, it works in two situations as explained below:
- Merging across single branch- Merging combines the commits fetched from a branch in the remote repository with its corresponding branch in the local repository. This is not the new branch on which a new team is working as a new feature. This was the same branch pulled from the master branch and merged into the same branch after commit.
- Merging across multiple branches – Merging combines the commits on the receiving branch with those from the merging branch.
In this case, suppose you decide to develop a new feature for Selenium by creating a separate branch for it. For this, the new feature branch is extracted from the master branch. You develop the new feature on this new branch for days or months. When you conclude that the functionality on the new branch is ready to be merged with the main master branch, you merge this new branch with the master branch to push your feature to a remote Selenium repository. This process will be more clear when explained in detail in the next series of Git workflow tutorials.
Fork
An open-source project like Selenium is maintained by a group of people. Now, since this is an open-source project, anyone can contribute to it. But only valid changes approved by a designated set of people should be pushed to the repository. This is done by restricting access to this repository. Similar to Wordpress send for review button. Otherwise, the code will be in complete chaos and the next version of Selenium will break all your scripts. To facilitate manageable collaboration, a feature of Github called Forking is used.
Note: Fork is a feature of Github and not Git.
A fork is simply your personal extension of an existing repository in Github. That is, when you navigate to an existing repository in Github and click on the little Fork button on the top right-hand corner of the page, Github will simply recreate the same repository under your username. Now, you can push changes or your newly developed features to the Selenium like it's your own repository. So, you have the originating Selenium repository and your forked repository. To understand how this helps in collaboration, refer to the tutorial on Git Forking workflow.
Pull Request
When you push changes or a developed feature from your remote repository to the upstream, pull request is used to raise a flag to the developers that you have pushed something to the repository.
After developing and testing the new feature developed in the forked repository, when you're ready to submit the new feature for merging with the upstream selenium repository you raise a pull request. Herein, you enter a message explaining the feature for review and submit the pull request. Now the developers will review your new feature, determine if the code conforms to the standards and conventions and whether the feature works as described. Finally, once the new feature passes all these checks, the developers will merge your pull request with the main repository.
Tag
Tag is the label attached to a stable commit of the repository to indicate a milestone in the repository's history. Alternately, the tag indicates stable versions of code to be released to the community. Refer tutorial on Git Tags and Github Tags.
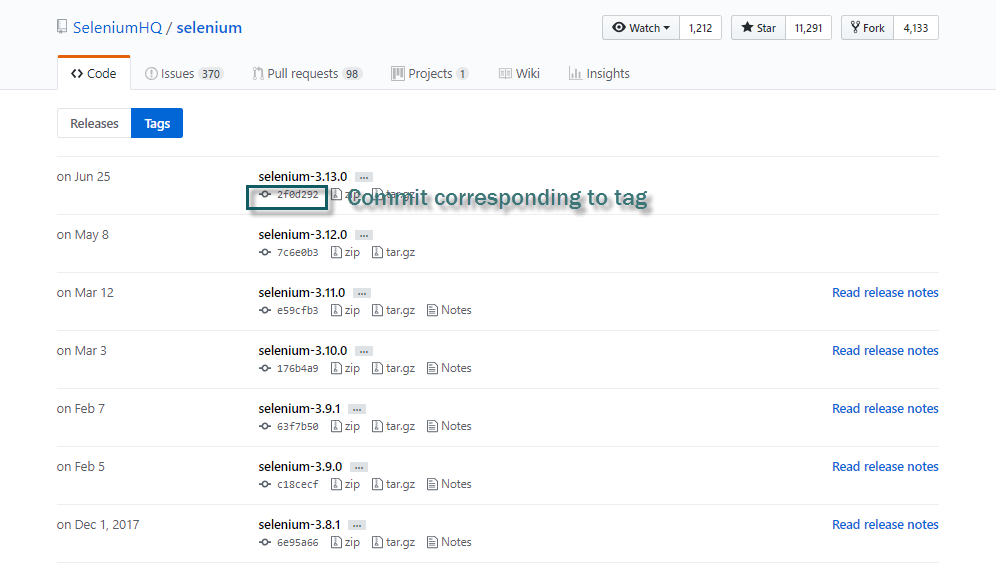
As seen in the above image, each tag, in turn, corresponds to a commit in the repository's history to be released as a specific version of Selenium code.
This brings us to the end of the tutorial on Git terminologies. Don't worry if you don't understand all of these terminologies completely. Usage of these terminologies in terms of workflows will aid in better understanding. Now let's take a look at Git Lifecycle.