In the previous tutorial, we learned about Version Control System. Then we looked at challenges faced by software teams in the absence of VCS and features of VCS. This article talks about different types of VCS and especially focuses on Distributed Version Control Systems (DVCS), which is the most common form of VCS that you will find in projects that require collaboration. In general, there are three types of Version Control Systems
- Local Version Control System
- Central Version Control System
- Distributed Version Control Systems
Local VCS
Local VCS, as the name suggests are Version Control Systems that track the changes to a file on a Local System. Usually, Local VCS would store the changes to a file in a Local Database. VCS, in general, have got advance these days. Instead of storing the new versions of the complete file, VCS now store only the difference between two versions. This saves memory cost.
Thus, the first version would be the actual file but each successive version would correspond to the difference between the current and the last version. Difference between the two such versions is called patch-sets. In Local VCS, a local database is used to track changes by storing the patch-sets. Any particular version could be recreated by adding the patch-sets up to that version.
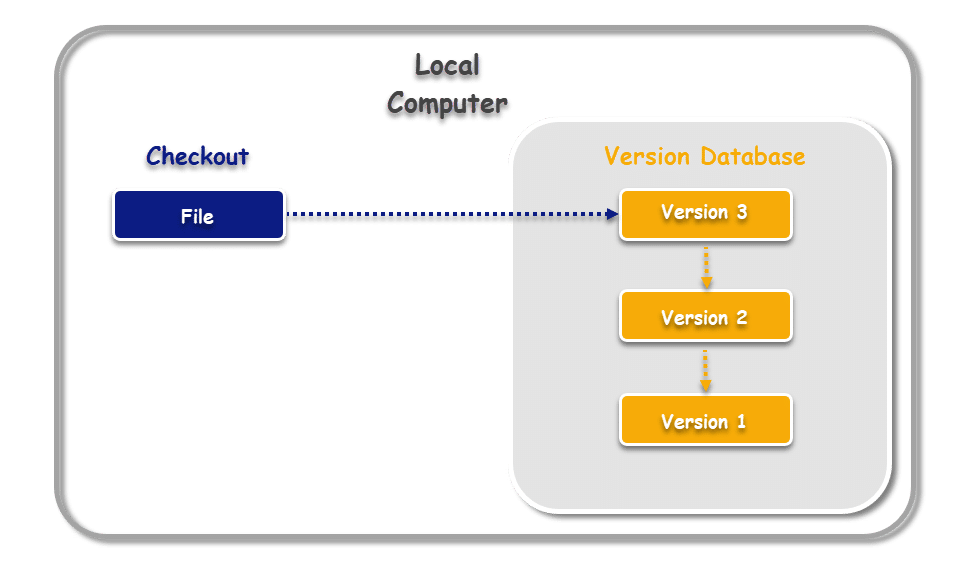
As shown in the image above, the local database stores Version 1, Version 2, and so on. These versions are groups of related files that have undergone changes since their last edit.
Note: Local VCS had a major drawback of being useful to only a single developer at a time. Thus, several developers working on different systems in a project could not collaborate effectively by using local VCS.
Central VCS
Central VCS is a step ahead in an attempt to overcome the limitation of several developers using individual local VCS to store patch-sets. Using Central VCS several developers are able to store their patch-sets in a single location at the central server. In this way, developers gain more visibility of features under development. Administrators also gain better control through the central server to define access-levels of different developers to the code. Developers could now simply download a particular version (also known as checking out) of files from the central server to their local machine. After making changes to these files, they could be uploaded back (aka committing) to the central server. In this way, team-members could collaborate and work from any local machine by simply connecting to the central server.
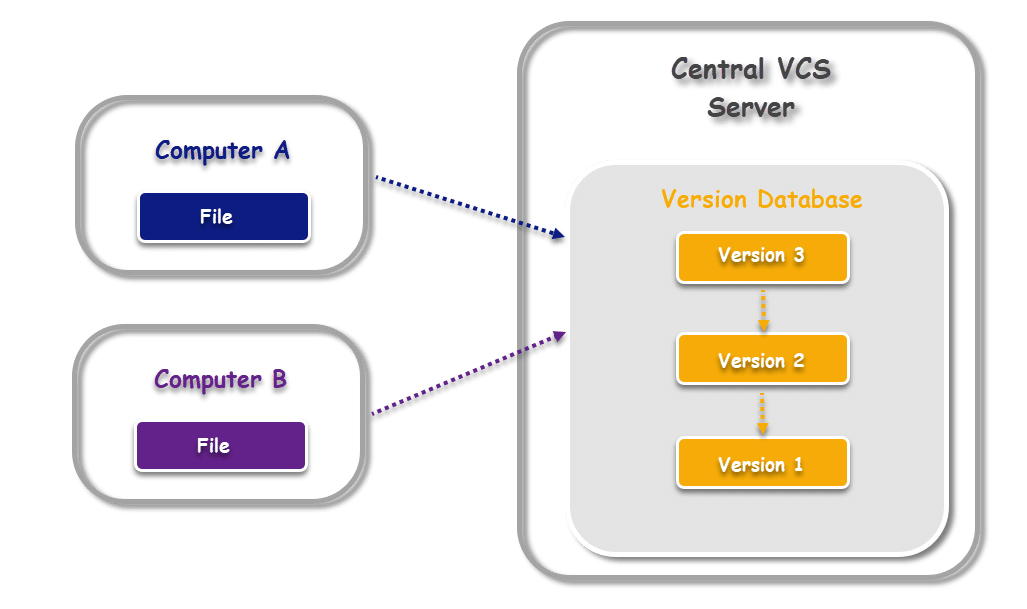
As seen in the image above, the version database housed in a central server stores different versions of files from multiple machines like Computer A and Computer B. Any local machine can check out any version of these files from the central server.
Note: Though central VCS helped developers and teams collaborate, there's a risk of an outage of the central server. Teams would neither be able to collaborate nor record changes of whatever they're working on due to such outages. Such servers are also prone to hacking. In such a case, it'd be pain-staking for teams to recover their work. Therefore it's not advisable to store all changes to code in a single place.
Distributed Version Control Systems (D-VCS)
Distributed VCS introduced significant improvement over the risks posed by Central VCS. In Distributed VCS, every local machine would have a copy of the entire code-base (aka repository) along with its history. Thus Distributed VCS moves from the client-server approach of Central VCS to peer-to-peer approach for version control. That is, in the case of Central VCS the central server would serve to requests for the latest code from local machines of the developers. However, with Distributed VCS, any of the local machines with the repository and history would serve the requests for the latest code.
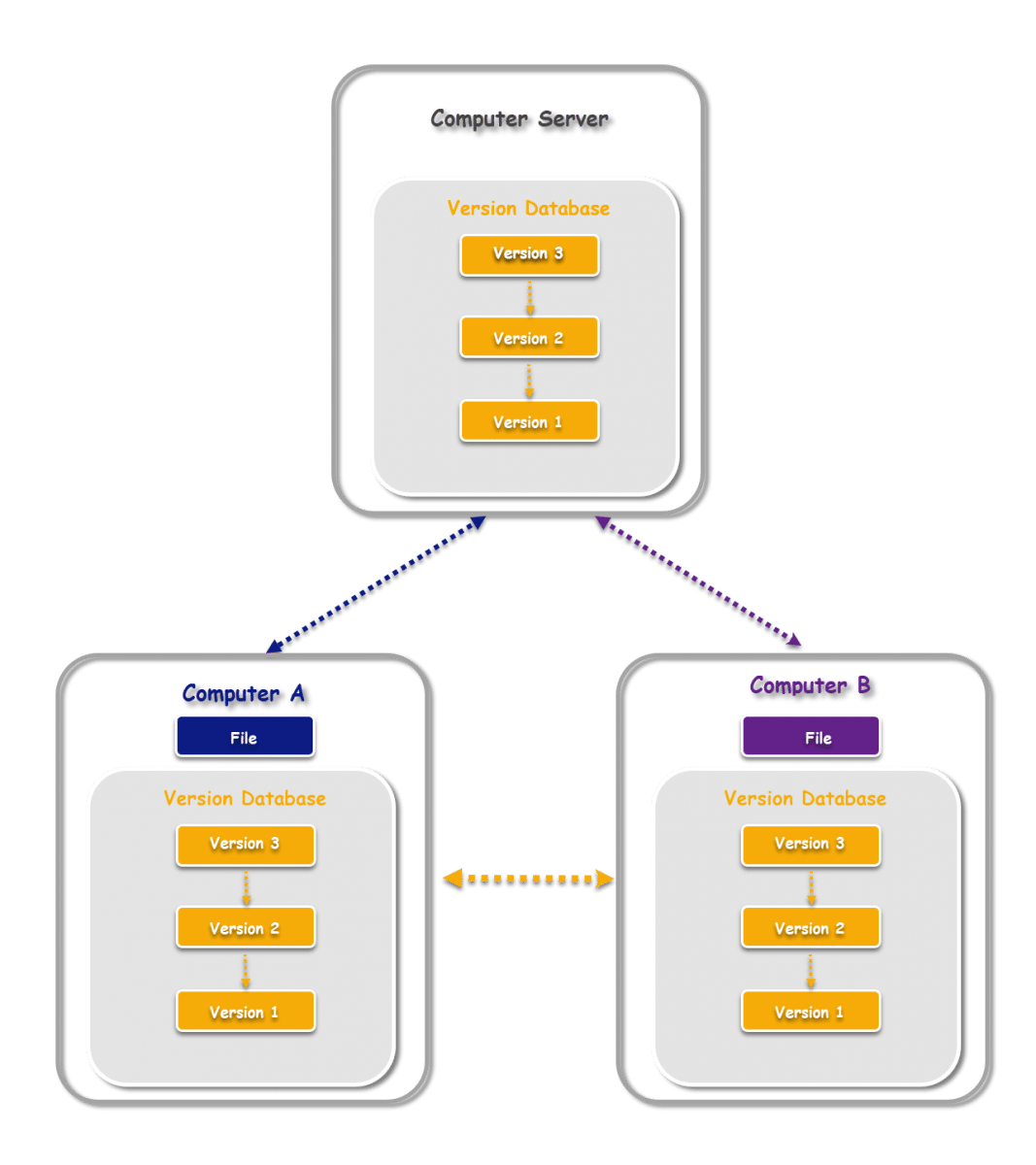
Note that the central server has the version database containing versions of files. Local machines mirror the same version database. This approach of storing the entire repository in every local machine might seem uneconomical at first. But the teams benefit immensely by using a repository cloned in one of the local machines to restore the repository to its original state in event of a crash. It's also important to note that Distributed VCS doesn't store exact progressive versions of the files. Instead, it stores just the patch-sets for tracking versions which decreases the volume of history stored on each local machine. Also, developers can record changes in their local machine while working offline. And then upload the new history of versions to the central server for others to view and use after connecting to the network.
Git, which we’ll be learning in this series is a Distributed Version Control system. Head over to the next tutorial to understand what is Git and Github.