

With the increasing trend of Microservices, it is becoming a need for each organization to build and deploy multiple services in parallel. In the same way, due to the increase in automated tests, it is becoming essential to execute the tests in parallel to reduce the overall execution time. It is where the CI tools need to provide a mechanism using which can share the load across various machines/servers. Jenkin's also provides this powerful feature of distributing build jobs ( Jenkins distributed builds) across a large number of machines. Using Jenkins, we can set up a farm of build servers to share the load or run the build jobs within various environments.
This ability also helps us configure Jenkins to fire distributed builds that can increase the efficiency and performance of the overall system. But, first, let's understand the overall capabilities of Jenkin's for scheduling and handling distributed builds by covering the details as mentioned in the following topics:
- What is a distributed build?
- Why are distributed builds required?
- Understanding Jenkins Distributed Architecture.
- Jenkins Master
- Jenkins Slave
- How to set up slaves/nodes in Jenkins?
- How to run builds using the distributed setup in Jenkins?
What is a distributed build?
In a build system, there might occur a situation wherein the current number of machines is inadequate, and we might need more machines to absorb the extra load. In addition, we might need extra machines to run specific tasks in specific environments. All these situations require the addition of more machines at a certain point in time during building. So how do we achieve this? The answer is distributed builds.
Distributed builds absorb extra load by "dynamically" adding extra machines as and when required, for example, in situations discussed above. Also, it may not be wise to run these builds on a single central machine for heavier projects that get built regularly. In this case, we can configure other machines as slaves that will take the load off the Jenkins master server. Let's understand a few of the significant reasons that justify the primary need for distributed builds:
Why are distributed builds required?
Below are a few of the main reasons that justify the need for distributed builds in a CI system:
- Fault Tolerance: We need to preserve information in the event of machine or data center failures or an entire wipeout of regions.
- Reduce latency: We need to reduce customer response time, which may spread throughout the world.
- Availability: If a machine breaks down or becomes slow, we need another machine nearby to serve the requests to avoid request failure. Monolithic system's availability is limited only to the piece of hardware it runs on. In the case of distributed systems, there are several machines, and availability is much improved.
- Durability: Distributed storage systems allow a great deal of flexibility around cost, durability, time-to-recovery, etc., by making multiple copies of a piece of data. They are also highly tolerant of correlated failures and can avoid correlation outright.
- Scalability: Distributed systems can offer better scalability. Since we distribute the system over many machines, we have a lot of flexibility to scale up the system.
- Efficiency: Needless to say, distributed systems are more efficient. Though workloads are seldom constant and we need to work on an hourly basis, every day, or even every minute, distributed systems can offer us automated scaling tools that provide better efficiency.
All these points help distributed systems be more efficient, scalable, and durable, and we can get our work done without too much load on a single machine.
Understanding Jenkins Distributed Architecture
The below image shows a basic setup for the Jenkins distributed architecture:
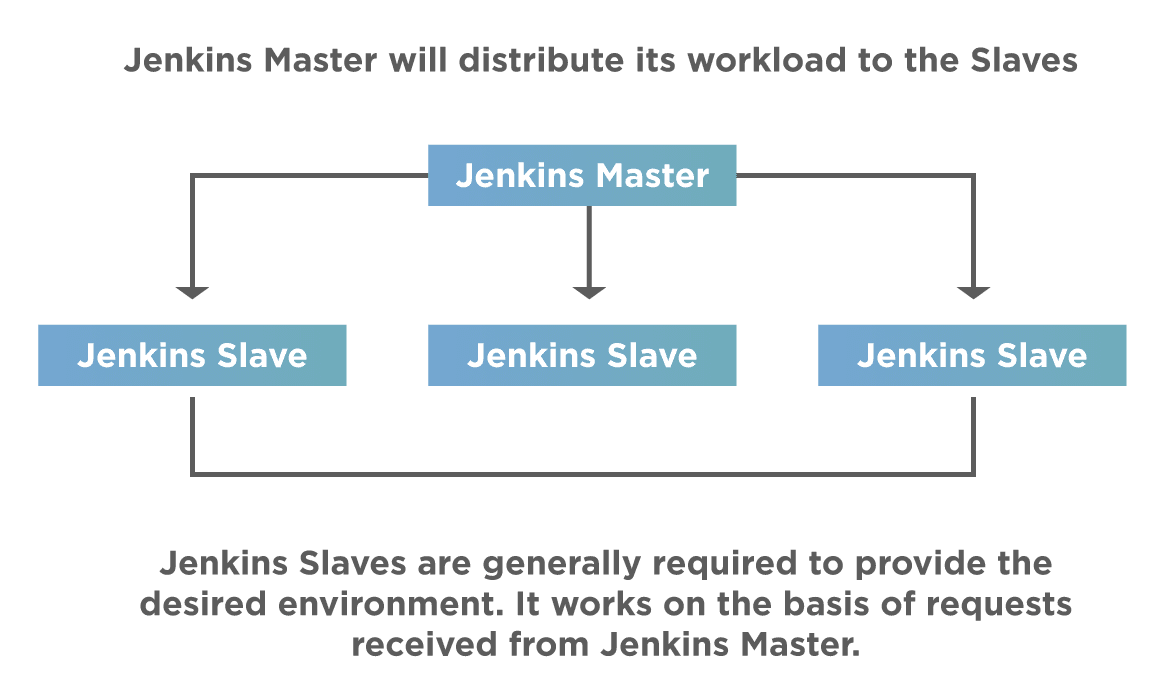
As seen above, Jenkins uses a Master-Slave architecture to manage distributed builds. The Master and the slaves communicate through TCP/IP protocol. Let's understand each of these components in more detail:
Jenkins Master
The Jenkins Master is the main Jenkins server and performs the following functions:
- It schedules the build jobs.
- Additionally, it dispatches the builds to the various slaves for the actual execution.
- It continuously monitors the slaves.
- Also, records the build results and presents them.
- If required, Master can also execute build jobs directly.
Jenkins Slave
A Slave runs on a remote machine and is a Java executable. A slave performs the following functions:
- It listens to requests from the Jenkins Master.
- Slaves can run on a variety of operating systems.
- Additionally, it executes build jobs that the Master dispatches.
- Apart from the fact that Jenkins always picks up the next available save to execute the build job, we can always configure the project to always run on a particular type of slave machine.
Let's now understand how we can set up the slaves in a Jenkins distributed architecture and how to schedule and run jobs on a slave.
How to set up slaves/nodes in Jenkins?
First of all, we need to have Jenkins installed on the machine before setting up slave nodes. Once done, we can follow these steps to set up slaves/nodes in Jenkins.
- Firstly, go to the "Manage Jenkins" section as shown below.
- Click on "Manage Jenkins" and scroll down to the section of "Manage Nodes" as seen & highlighted below:
- Click on New Node as highlighted below:
Here, specify a name for the node. For example, in Slave1, choose the Permanent Agent option and click on the OK button.
- Now, it will show the node screen wherein we have to enter the data regarding the node as shown below:
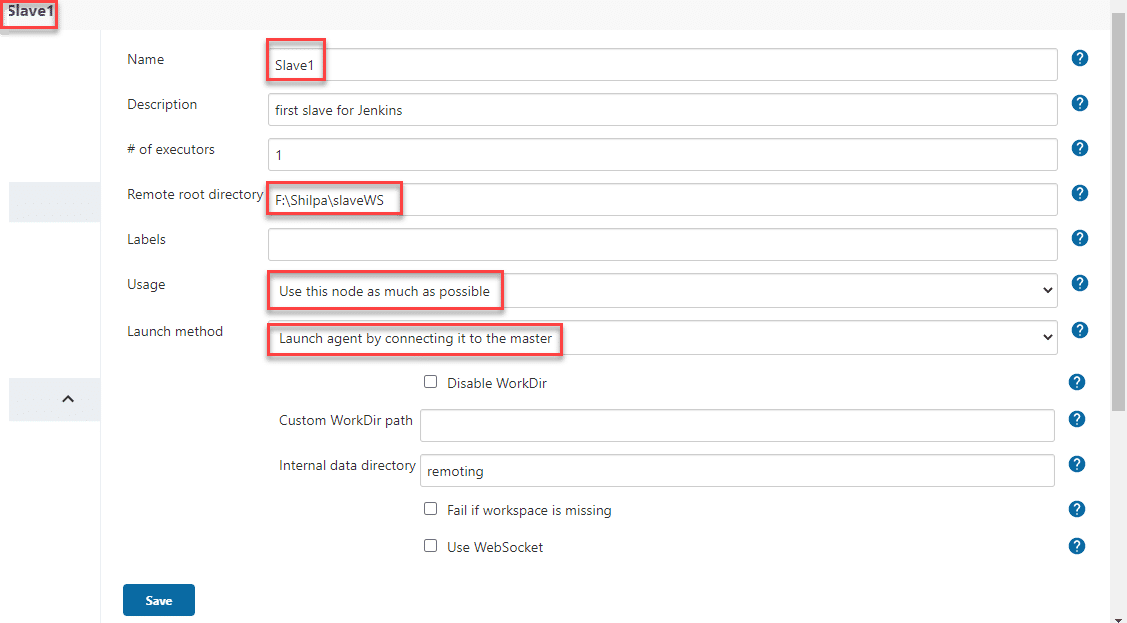
We will enter the details of the slave node machine here.
- The number of executors is the number of jobs this slave can run parallelly. Let us keep it at 1.
- The 'Labels' is the label for the node, and we can specify 'Slave1' as a label or keep it blank.
- Select Usage as "Use this node as much as possible."
- For the launch method, select the option of “Launch agent by connecting it to the master.”
- Enter/ set Custom WorkDir path as the workspace of your slave node.
- In Availability, choose/ select “Keep this agent online as much as possible.”
- Click on Save.
Note: If the option "Launch agent by connecting it to the master” is not visible under the launch method, then go to Jenkins home page -> Manage Jenkins -> Configure Global Security. Here in the Agents section, select/ click on Random and Save it.
Once you complete the above steps, the new slave node appears in the list of nodes as seen below:
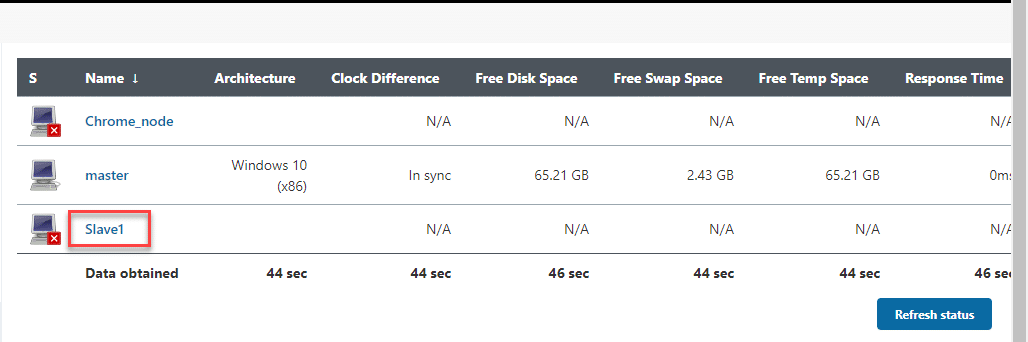
Initially, the new node machine will be offline but will come online if all the previously set settings are correct. We can make slave nodes offline as and when required.
Let's now see how we can run the builds on this slave machine:
How to run builds using the distributed setup in Jenkins?
Now that we have set up the slave node, we can execute the build job on this slave node. But, first, let us run an existing job on the slave. For this, open the job (in the job list on Jenkins Dashboard) and click on the "Configure" option. It will open the Job's configuration page, as shown below:
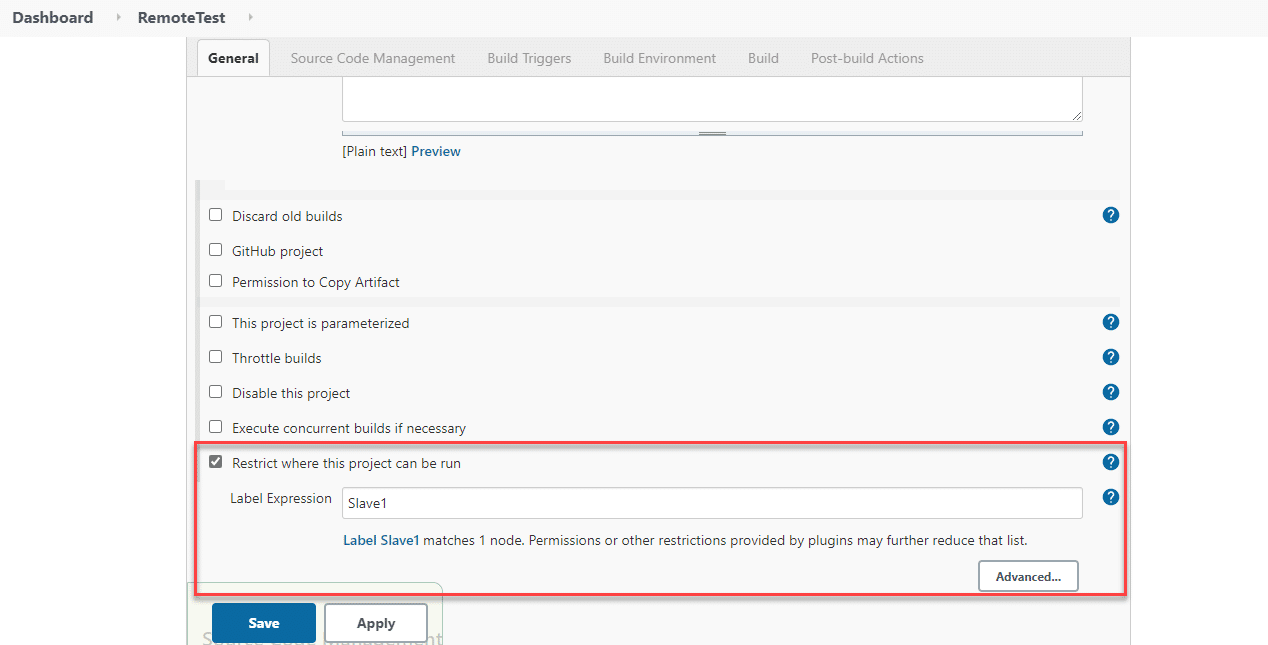
Here in the General section, click on “Restrict where this project can run,” and then in Label Expression, enter the name of the slave (Slave1 we created above) and save it.
Now build the job and check the output of the job. The build now is running on the slave selected, and we can verify the same in the left panel of Jenkins, where it will list all the jobs and the slaves on which the job is running.
Key TakeAways
- Distributed builds increase the efficiency of the build process when we have to build a big project and the load needs to distribute among various machines in the network.
- Jenkins handles the concept of distributed builds using the Master/Slave architecture.
- Once we create and configure the slave node, we can associate a project with this node and then schedule it for the build.










