Volumes store the data generated by Docker. Using Docker Volume, we can achieve data persistence within Docker Containers. We can share directories between container and container versions using Docker Volumes. Also, we can upgrade containers, restart machines or share data without losing it. So let us discuss more of the Data persistence and Docker Volumes in this article. We will cover the following topics as part of this tutorial.
- How to manage data in Docker?
- Volume vs. Bind Mount in Docker
- How to use Mounts in Docker?
- How to use data volumes?
- The -v or -mount flag?
- Create and manage Docker data volumes.
- How to use data volumes with docker-compose?
- What are read-only data volumes?
- Start a container/service with Docker data volume
- How to populate a Docker data volume using a container?
- What is a Volume driver?
- Initial set-up - docker plugin install command
- Create a data volume using a volume driver - docker volume create command
- Start a container that creates a volume using a volume driver
- Backup, restore, migrate, or remove data volumes in Docker
- Backup a container
- Restore container from backup
- Remove docker volume
How to manage data in Docker?
We know that Docker has a layered storage implementation that aids in portability, efficiency, and faster performance. This storage implementation is also optimal for retrieving, storing, and transferring images across various environments. When we delete a Docker container, all the data associated or written to the container is deleted with it. So there is a need to persist the container data somehow even when the container gets deleted so that we need not worry about data and persist this data after the container ceases to exist.
Hence there is a need to persist data in containers. One of the best-recommended practices is the isolation of data from the container to retain the benefits of containerization. Here we keep data management distinctly separate from container lifecycle. We can implement multiple strategies to persist data or add persistence to containers that we will discuss next. These strategies are as shown in the diagram below.
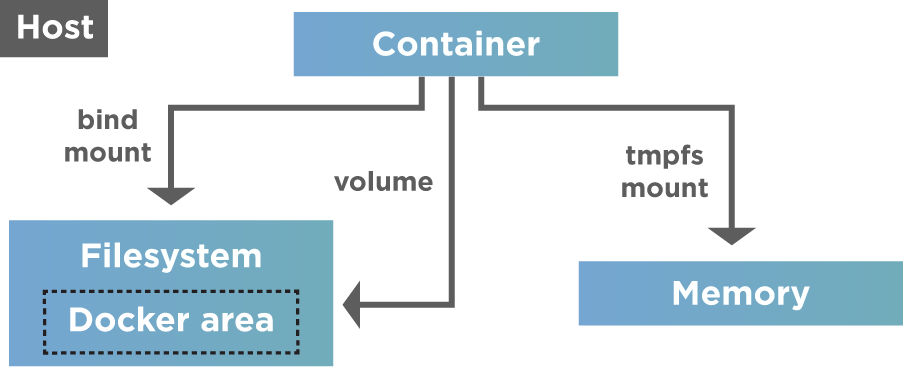
As shown above, Docker provides two options for data persistence so that files are persisted even after the container stops.
- Volumes
- Mounts
Let's understand the difference between these two:
Volume vs. Bind Mount in Docker
- Volumes: Volumes are directories or files that are outside the Union file system(the combination of read-only layers with a read-write layer on top of the container). Volumes exist/ store as normal files and directories on the host filesystem. Hence to persist and share data between containers, Docker uses Volumes. Volumes are the best option to persist data in Docker containers. Docker manages volumes and is stored in a part of the host filesystem (/var/lib/docker/volumes/ on Linux).
Note: Processes not part of Docker (non-docker processes) should not modify this portion of the filesystem.
- Mounts: In Docker, we can use the following mounts.
- Bind mounts: A file or folder stored anywhere on the container host filesystem and mounted into a running container is called a bind mount. They can be anything from essential system files to directories. Interestingly, Docker container or Non-Docker processes present on the Docker host can modify these mounts at any time.
- tmpfs mounts are used mainly by Docker running on Linux systems. Their storage is in the host system’s memory only. Additionally, we never write the tmpfs mounts to the host system’s filesystem. Contrary to volumes and bind mounts, the "tmpfs" mount is temporary and only persisted in the host memory. When the container stops, the "tmpfs" mount removes, and files written there won’t persist.
Note: If the Docker is running on Windows, we can use the named pipe.
The Docker volumes are widely used and useful tools for data persistence when working with Docker containers. Compilation of additional writable layers adds to the image size, and hence volumes are the better alternative. Secondly, the volumes are independent of the container life cycle and stored on the host. Because of this, we can back up data and share file systems between one or more containers easily.
For now, just keep in mind these methods, as the details will be shared later in the post.
How to use Mounts in Docker?
When we use bind mounts, we can control the exact mount point, a directory (typically an empty one) in the currently accessible filesystem on which additional filesystem mounts (i.e., logically attached) we want the host system. Apart from using bind mounts to persist data, it often provides additional data to containers. Using bind mounts to mount source code into the container lets us see code changes right away and respond.
The question now arises as to which mount should we use and when?
Although we should generally use volumes as far as possible, bind mounts are appropriate in the following use cases:
- When we need to share configuration files to containers from the host machine. For instance, to provide DNS resolution to containers, Docker mounts "/etc/resolv.conf" into each container from the host.
- When we want to share the build artifacts or source code between the development environment and container on the host machine. For example, we may mount, say, the Maven 'target/' directory into a container. Thus each time we build the Maven project on the host, the container will access the updated artifacts.
- We can also use bind mounts when the directory or file structure of the Docker host is consistent with the bind mounts required by containers.
So discussed above are some of the cases or situations where we find bind mounts useful.
On the other hand, we can use tmpfs mounts when we do not want to persist data on the host machine and the container. It is mainly for security reasons and protects the container performance, especially when the application has to write large non-persistent data volumes.
As evident from the above discussion, we use tmpfs mounts seldomly. Nonetheless, we should keep in mind a few tips when working with bind mounts and volumes.
- When we mount an empty volume into a directory inside the container, the files and/or directories inside the container propagate into the volume.
- When we start the container and specify a volume that does not exist, Docker creates an empty volume.
- Similarly, when we mount non-empty volumes or bind mounts into a directory inside the container which already has some files and/or directories, then these files and/or directories are obscured by the mount and are not accessible while the volume or bind mount is mounted.
In the remainder of this article, we will discuss volumes in detail.
How to use data volumes?
Volumes are popular and preferred mechanisms for data persistence in Docker containers. As against bind mounts dependent on the OS and directory structure of the host machine, volumes are managed entirely by the Docker. Some of the advantages of volumes over bind mounts are as follows:
- We manage volumes using Docker API commands.
- Volumes are supported both by Linux and Windows.
- It is easier to back up or migrate volumes as compared to bind mounts.
- We can quickly and safely share volumes among multiple containers.
- Using volume drivers, we can also store volumes on remote hosts or cloud providers. We can also encrypt the contents of volumes or add any other functionality.
- The container can pre-populate the new volumes.
- Volumes on Docker Desktop perform more efficiently than bind mounts from Windows or Mac hosts.
Volumes do not increase the size of the containers that are using them, and also, contents of the volume exist outside the lifecycle of that container. Hence volumes are a popular choice for persisting data. The following diagram shows volumes and mounts in action.
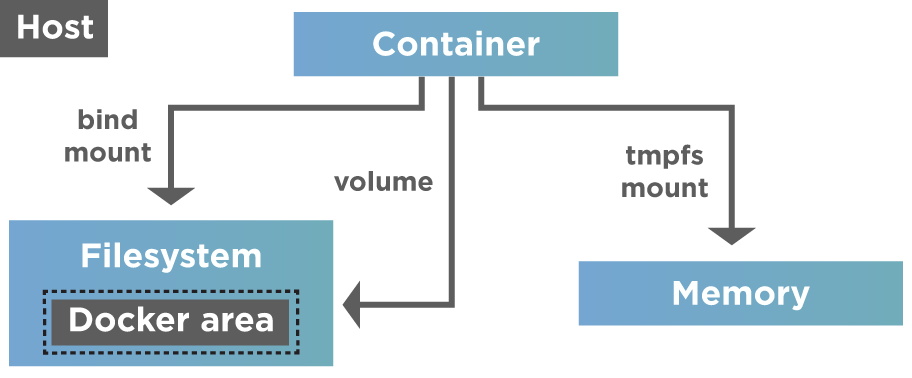
So if the container has to store non-persistent data that is temporary, we should ideally consider using tmpfs mount. For other things like storing data permanently or writing it into the container's writable layer, we go for volumes or bind mounts.
The -v or -mount flag?
As far as volumes are concerned, they use private bind propagation, and we cannot configure bind propagation for volumes.
As to the options --mount or --v, --mount is more verbose and explicit. The main difference between --v and --mount is that the --v syntax combines all options in one field, whereas the --mount syntax separates them.
For specifying volume driver options, we should use --mount.
- -v or --volume: This option consists of three fields separated by a colon (:). We must ensure that the fields are in the correct order. Field descriptions are as below.
- For anonymous volumes, the first field omits. In the case of named volumes, the first field contains the name of the volume. The name is unique for a given host machine.
- The second field contains the path of the location of the file or directory mounted in the container.
- The third field is optional. It contains a comma-separated list of options, such as ro.
- --mount: This option contains multiple key-value pairs, separated by commas (,) with each consisting of (<key>=<value>) tuple. Note that the syntax for '--mount' is more verbose than '--v' or '--volume'.
- The type (type) of the mount: This can be bind, volume, or tmpfs.
- The source of the mount(source/src): For named volumes, this field contains the volume's name. We omit this field for anonymous volumes.
- The destination(destination/dst/target): This field has the value of the path where the directory or file is mounted.
- The readonly option: When present, this field makes the bind mount to mount as read-only.
- The volume-opt option: This field consists of key-value pairs with option name and value. It can be specified more than once.
Now let us tabularise the main differences between --v and --mount options.
| Property | Named Volumes | Bind Mounts |
|---|---|---|
| Host Location | Chosen by Docker | User-controlled |
| Mount Example (using - v) | my-volume:/usr/local/data | /path/to/data:/usr/local/data |
| Prepopulate new volume with container contents | Yes | No |
| Volume Drivers support | Yes | No |
Note: Contrary to bind mounts, all the options for volumes are present for --mount as well -v flags. When we use volumes with services, only --mount is supported.
In the next section, let us go through Docker commands related to volumes.
Create and manage Docker data volume
Volumes can be created and managed outside the scope of any container. To create a docker volume, use the 'docker volume create' command on the console. The command to is given below.
$ docker volume create my-vol
We can list the existing volumes using the following command.
$ docker volume ls
Given a volume, we can retrieve its details by using the "docker volume inspect command".
$ docker volume inspect volume_name
The following screenshot shows the working of the above commands.
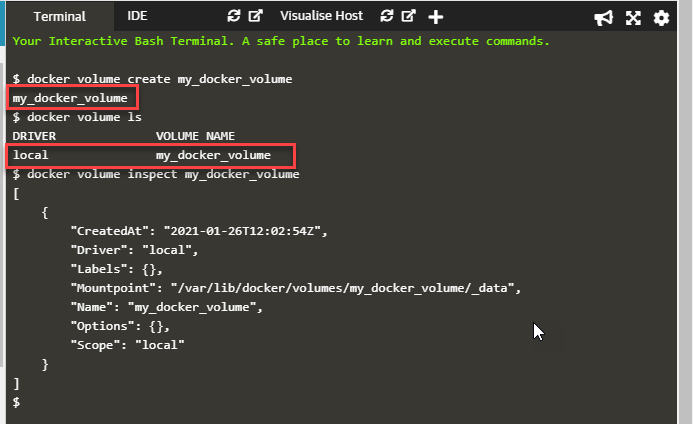
As shown in the above screenshot, we have created a new volume, "my_docker_volume" with the docker volume create command:
docker volume create my_docker_volume
The next command, "docker volume ls", lists the volume just created. Next, we specify the command:
docker volume inspect my_docker_volume
This command gives the details of the volume, as shown in the above screenshot.
Similarly, we can use the following command to remove the volume.
$ docker volume rm Volume_name
Hence to remove the volume created above, we can specify the command,
docker volume mu_docker_volume
The result of the command is as shown below.
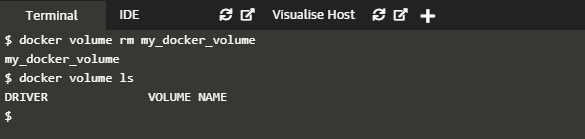
To verify that we indeed removed the volume, we can give the command "docker volume ls".
How to use data volume with docker-compose?
We can also create a volume with Docker compose service or also specify existing volumes. For example, the following screenshot shows a 'docker-compose' file that creates a docker-compose service with a volume.
The command is as follows:
docker-compose up
Output generated:
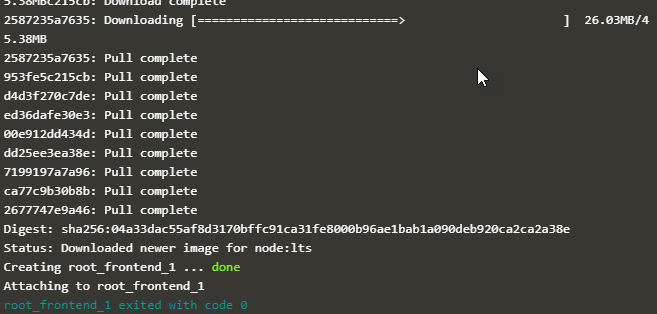
As a result of the above command, a volume with the name 'myvolume' gets created. Subsequent invocations of 'docker-compose up' will reuse this volume.
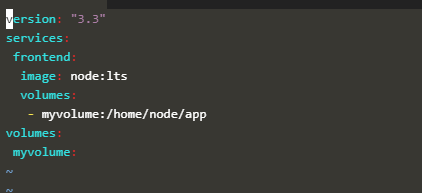
Alternatively, we can also create a volume outside of Docker Compose and then reference it inside the 'docker-compose.yaml' file, as shown in an example below.
version: "3.3"
services:
frontend:
image: node:lts
volumes:
- myvolume:/home/node/app
volumes:
myvolume:
external: true
In the above docker-compose file, we have used the volume with the name 'myvolume'. Note that a flag 'external' is specified and is set to true that indicates the volume already created outside the docker-compose.
What are read-only data volumes?
In most cases, the container only needs access to the data for reading purposes. Also, some folders may change a lot, and it might be difficult and costly to create images for each execution. In this situation, we go for read-only volumes.
To specify the volume as read-only, we append 'ro' to the -v switch as shown below:
docker run -v volume-name:/path/in/container:ro my/image
We can also use the "mount" switch with the 'readonly' option, as shown below.
$ docker run --mount source=volume-name,destination=/path/in/container,readonly my/image
We use read-only volumes in the case of dynamic data used in the application.
Start a container/service with Docker data volume
When we start a container with the non-existing volume, Docker creates a new volume with the specified name. The following example shows this.
Here we give the following command.
docker run -d --name volumetest -v my_docker_volume:/app ubuntu:latest
As shown in the above command, a new container, "volumetest", is started with the specified volume name as "my_docker_volume". This volume is non-existing. On execution of the above command, we get the ID of the container volumetest. To verify that we actually created the volume, we can give the inspect container command as follows:
docker inspect volumetest
When this command executes, we can directly jump to the "Mounts" section of the inspect output, as shown in the below screenshot.

As seen in the above screenshot, we have the details of the volume created. volume' and the read-write option is true for this mount. We can then stop the container and remove the volume with the following sequence of commands.
$ docker container stop volumetest
$ docker container rm volumetest
$ docker volume rm my_docker_volume
When a service starts and we define a volume, each service container will use its local volume. So if we use a local volume driver, no container will share the data. But there are exceptions wherein some volume drivers support shared storage. For example, Docker for AWS and Azure uses the Cloutstor plugin to support shared persistent storage.
Starting the service with the local volume is similar to that of starting a container. The difference is that in the 'docker service create' command, the '-v' or '--volume' flag is not supported. Instead, we must use the '--mount' flag for mounting the volume.
How to populate a Docker data volume using a container?
When we start a container that creates a new volume, and if the container has files and directories inside it, then the contents of this directory are copied into the volume. Thus, the container that mounts this volume and other containers that use this volume will have access to pre-populated contents.
As an example, we give the following command to start the ubuntu container and populate the new volume "ubuntu_vol" with the contents of the "/usr/share/ubuntu/html" directory.
docker run -d --name=mounttest --mount source=ubuntu_vol,
destination=/usr/share/ubuntu/html ubuntu:latest
After this, we can clean up the containers and volumes by executing the following sequence of commands.
$ docker container stop mounttest
$ docker container rm mounttest
$ docker volume rm ubuntu_vol
Apart from this command, we can also prepopulate the volume with the command used in the previous section to start the container.
What is a Volume driver?
We can use volume drivers when we need to store volumes on remote hosts or cloud providers to encrypt the contents of volumes or add more functionality. For example, when we use the "docker volume create" command, or we start a container with a non-existing volume, we can specify the volume driver. One of the examples of the volume driver is "Vieux/sshfs". In this section, we will just touch base with the basics of volume drivers.
Initial set-up - docker plugin install command
The first step in using the volume driver is to install the appropriate plugin. For example, we can install the plugin vieux/sshfs with the following command.
$ docker plugin install --grant-all-permissions vieux/sshfs
It will install the volume driver plugin on the docker host.
Create a data volume using a volume driver - docker volume create command
The next step is to use the just installed plugin to create a volume.
$ docker volume create --driver vieux/sshfs \
-o sshcmd=test@node2:/home/test \
-o password=testpassword \
sshvolume
We have specified an SSH password in the above command, but we can omit it if two hosts configure with shared keys. The flag '-o' specifies zero or more configurable options (like username and password in the above command).
Start a container that creates a volume using a volume driver
After installing the plugin, we can also start a container by specifying the volume driver's non-existing volume. Docker will create a new volume while starting the container. The following example shows creating an Nginx container with the "vieux/sshfs" volume driver.
$ docker run -d --name sshfs-container --volume-driver vieux/sshfs --mount src=sshvolume,
target=/app,volume-opt=sshcmd=test@node2:/home/test,
volume-opt=password=testpassword nginx:latest
Again we can omit the password if there are shared keys, and there can be zero or more configurable options specified with 'volume-opt'. Remember to use '--mount' flag to mount the volume when the volume driver needs to pass options.
Backup, restore, migrate, or remove a data volume in Docker
We can use volumes for migrations, backups, and restores. Let us discuss these with volumes.
Backup a container
We follow the following steps to back up a container.
- Create a new container
- Launch a new container and mount the volume from the container created in step 1.
- Mount localhost directory as /backup
- Tar the contents of the volume to backup.tar file inside the /backup directory.
Thus we have a backup of the volume in /backup local directory. Let us take an example to illustrate these commands.
First, we create a new container with the following command:
docker run -v /dbdata --name dbcontnr ubuntu /bin/bash
Next, we can create a backup directory or backup the volume in the present directory itself. Once this happens, we execute the following command to tar the volume contents.
docker run --rm --volumes-from dbcontnr -v $(pwd):/backup ubuntu tar
cvf /backup/backup.tar /dbdata
The following screenshot shows the result of the execution of the above commands.
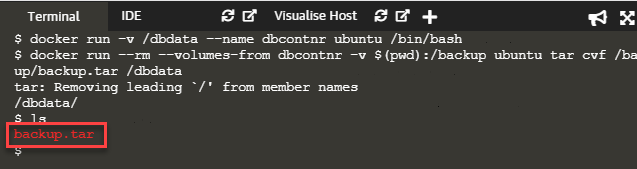
When we list the contents of the current directory, we can see the backup.tar file of dbdata volume created on the host machine.
Restore container from backup
Now that we have created a backup, how do we restore it to the container? We can either restore the backup to the exact container or another container. First, let us restore the backup we created in the previous section to a new container. For this first, we create a new container as follows.
docker run -v /dbdata --name dbcontainer2 ubuntu /bin/bash
Now we restore the backup (backup.tar) to this container as follows:
docker run --rm --volumes-from dbcontainer2 -v $(pwd):/backup ubuntu bash -c
"cd /dbdata && tar xvf /backup/backup.tar --strip 1"
Once the command is successful, the container 'dbcontainer2's' data volume will have the contents of untar file into it.
We can use these techniques of backup, migration, and restore to automate the entire process.
Remove docker volume
The data volume of a Docker container persists even after the container deletes. A Docker data volume persists after a container deletes. We have two types of data volumes:
- Named volumes: Named volumes have a specific source that is outside the container, for example awesome : /hello.
- Anonymous volumes: These volumes do not have a specific source when the container deletes. We should instruct the Docker Engine Daemon in case we need to remove them.
To remove anonymous volumes automatically, we use the "-- rm" option. For example, if we have an anonymous /bkup volume. Then, when the container deletes, the Docker Engine will automatically remove the /bkup volume with the following command.
$ docker run --rm -v /bkup -v awesome:/hello busybox top
The above command creates an anonymous /bkup volume. So when we remove the container, the Docker Engine removes the /bkup volume but not the awesome volume.
To remove all the unused volumes, we can use the following command:
$ docker volume prune
It removes all the volumes that are unused and frees up space.
Key TakeAways
- There are mounts that we can also use for persisting data apart from volumes.
- When we create a container and specify a non-existing container, the Docker creates the volume for us.
- We can also create a volume and then use it with a container using the -v flag.
- Docker-compose allows us to use volumes that are either existing or new.
- Using volumes, it is easier to backup, migrate and restore data and even automate the entire process.