In our earlier articles, we have discussed significant concepts of Docker and also Docker compose concept that is helpful to run multiple containers simultaneously. This article will introduce yet another concept called "Docker Swarm," which makes Docker works across various nodes and allows these nodes to share containers. Subsequently, in this article, we will discuss the overview of Docker Swarm with the following topics:
- What is Docker Swarm?
- Why and When do we use Docker Swarm?
- How does Docker Swarm work?
- What are the key concepts in Swarm mode?
- Setting up Docker Swarm cluster
- Swarm Mode CLI commands
- Kubernetes vs. Docker Swarm
What is Docker Swarm?
A Docker Swarm is a group/ cluster of machines (either physical or virtual) that run the Docker application and configure it to join together in a cluster. Once a group of machines that run the Docker application has been clustered together, we call it a "Swarm mode". So in Swarm mode, we can still execute Docker commands with the only difference that now the machines in the cluster will execute them. Moreover, we have an entity called "Swarm Manager", a machine that controls the activities of a cluster. Other machines that have joined the cluster are known as "Nodes".
At a high level, we can view the Docker Swarm as an orchestration management tool. Docker Swarm runs on Docker applications and helps the developers/end-users create and deploy a cluster of Docker nodes. Additionally, a high-level availability for applications is one of the key benefits offered by Docker swarm. For example, we can schedule the application tasks so that each machine in the Swarm cluster has one task each. Moreover, it helps in the efficient distribution of tasks and reduces the turnaround time for the tasks, thus increasing the throughout.

The above image shows a Docker Swarm mode with numerous docker containers. In Docker Swarm mode, each node is a Docker daemon (used to run Docker on the system), and all these Docker daemons interact with each other using the Docker API. Additionally, we can deploy each container within the Swarm, and nodes of the same cluster can access them.
Any given Docker host can be a manager node, a worker node, or perform both roles. A task in Docker Swarm is a running container, and the Swarm manager manages it. It is not a standalone container.
Below given are some of the essential features of Docker Swarm:
- Decentralized access: Using swarm, it becomes easy for teams to manage and access the environment.
- High security: Communication between swarm nodes is very secure.
- Autoload balancing: Swarm has autoloaded balancing within the environment. Moreover, we can script this feature to structure the Swarm environment.
- High scalability: The load balancing feature allows us to create highly scalable applications.
- Roll-back a task: In Swarm mode, we can roll back environments to previous safe environments.
- Highly Available Applications: Swarm cluster makes applications highly available.
- Desired State Reconciliation: As the state of the cluster is under constant monitoring, any differences between the actual and desired state of the cluster reconcile immediately. For example, suppose any one of the replicas of Docker host crashes in a cluster. In that case, the Swarm manager assigns a new replica running and available to the worker node whose replica has crashed.
- Rolling updates: We can also apply service updates to nodes in the cluster incrementally at rollout time. If anything goes wrong with these updates, we can conveniently roll back to the previous version of the service.
Why and When do we use Docker Swarm?
While we have seen the overview of Swarm mode and its working along with key concepts, the question remains as to why we have to use Docker Swarm? Let us discuss the use case of Docker Swarm briefly.
Let’s consider we have one application server that can serve the 'n' number of clients. If we need to serve twice the amount of clients, i.e., 2n, we may have to increase the resources on the server or create another instance of the application server and load balance it with the first server.
As the number of clients to serve increases, we increase the cluster by commissioning additional application servers. Mostly we do it manually, but some servers have built-in cluster features to help speed up and automate the commissioning of additional nodes in the cluster. Docker comes here and provides a way to create a “swarm” of cluster nodes by creating the required number of application containers. Docker allows us to deploy any number of application servers over any number of hosts using very few commands. This way, we can scale the applications quickly.
Before we consider moving to Docker Swarm, it is advisable to answer the following questions to help us decide where exactly we should use the Swarm?
- Do we need scaling beyond one host?: Using multiple servers is always complicated than using a single server. So will the server with more advanced features solve our problem, or is it necessary to have multiple servers?
- Do we need high availability?: Decide whether we need high availability or we can do without it.
- Are the containers used truly stateless?: Swarm containers shouldn't use any volumes. But although this is possible theoretically, it may not be possible practically. One option is to move media files and databases out of swarm so that we can nearly have stateless containers.
- Do we need a log aggregation system, such as ELK stack?: Log aggregation system applies to all distributed systems.
- Do we really need advanced features?: We should decide if we want features of Docker Swarm in our application environment or more advanced features like Kubernetes.
When we have affirmative answers to all the above questions, we will be able to decide whether our application environment needs to use Docker Swarm or not. Next, we go through a few Swarm mode commands.
How does Docker Swarm work?
In Swarm mode, 'services' are used to launch containers. Moreover, we can define a service as a group of containers belonging to the same image to scale the applications. Note that before deploying a service in Docker Swarm mode, we must deploy at least one node.
The worker nodes use API over HTTP to communicate with the manager node. In Swarm mode, any node of the same cluster can deploy and access services. Moreover, we have to specify which container image to use when creating a service. Additionally, we can use services in two ways: Replicated and Global services. In the replicated services model, the swarm manager assigns a specific number of replicated tasks to the nodes based upon the service scale. Similarly, for global services, the Docker Swarm runs one task for the service on each node present in the cluster.
We have three types of nodes in Docker Swarm:
- Manager node: A manager node manages membership and delegation. Additionally, it also handles cluster management tasks.
- Worker node: A worker node receives and executes tasks and services from the manager node.
- Leader node: The leader node is the primary manager node. Additionally, it makes all swarm management and orchestration decisions for the swarm cluster.
Here a task is a running container that is part of a swarm service. Contrary to the standalone container, a swarm manager manages the task. Subsequently, the following diagram shows a typical Docker Swarm cluster.
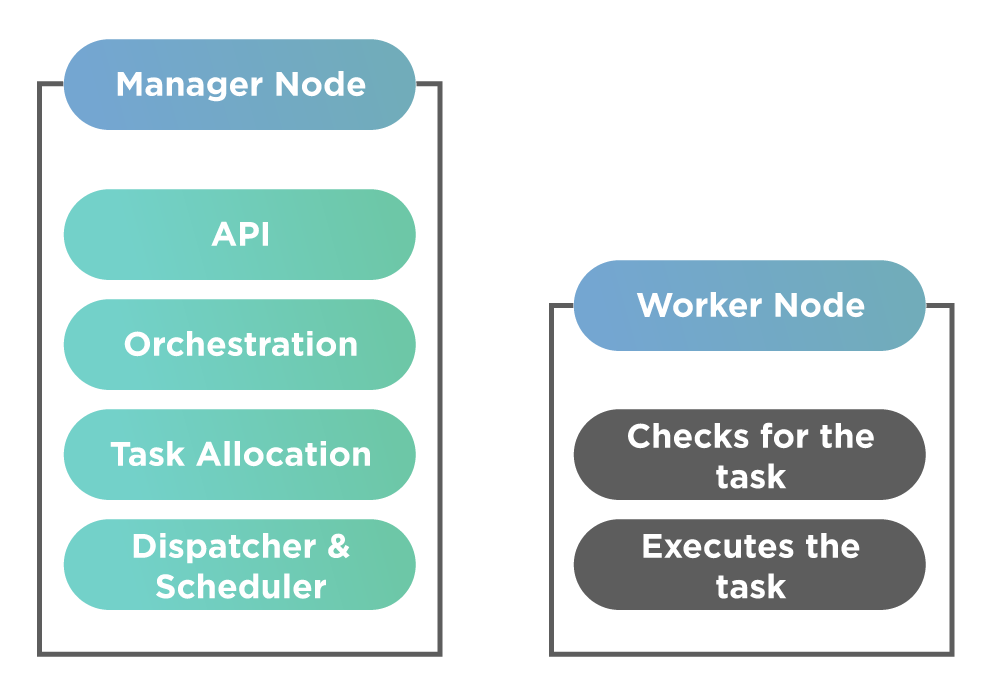
The above diagram shows a manager and a worker node in the Swarm cluster. The manager node is aware of the status of the worker nodes in a cluster. Additionally, the worker nodes check for the tasks and accept them from the manager node. Each worker node has an associated agent whose job is to report back to the manager node on the state of the node's tasks. Moreover, it helps the manager node to maintain the desired state of the cluster.
So is task and service the same thing? The answer is NO.
A task is work to be done, and service is a description of that task or the state. Using Docker, we can create services that can start tasks. Once a task is assigned to a particular node, we cannot assign it to another node. Additionally, we can have multiple manager nodes in a Swarm cluster, but other manager nodes will elect only one primary manager node.
As shown in the above figure, a Docker Swarm environment has an API that allows us to do orchestration by creating tasks for each service. Each service is created based on the command-line interface. Additionally, the work gets allocated to tasks via their IP address(task allocation in the above figure). The dispatcher and scheduler are responsible for assigning and instructing worker nodes to run a task. The Worker node connects to the manager to check for new tasks. The last stage in this process is for the worker node to execute the tasks that have been assigned from the manager node.
It briefly summarizes the work of Docker Swarm. Subsequently, now let us understand some of the key concepts in Docker Swarm mode.
What are the key concepts of Swarm mode?
Following are the key concepts related to Docker Swarm.
Nodes
A node is an instance of the Docker engine participating in the swarm cluster. We also refer to it as Docker Node. One or more nodes can execute on a single physical machine or cloud server. Still, in an actual production swarm environment, we have Docker nodes distributed across multiple physical and cloud machines. As already seen above, we have two types of nodes in Docker Swarm, namely, manager node and worker node.
When an application deploys to a swarm, we submit a service definition to a manager node. The manager node then dispatches units of work or tasks to worker nodes. The manager node is also responsible for orchestration and cluster management function that helps maintain the swarm's desired state.
Worker nodes are responsible for executing tasks that dispatch to them from manager nodes. An agent runs on each worker node and reports to the manager node on its assigned tasks. It helps the manager node to maintain the desired state of each worker node.
Services and tasks
Service is the definition of the tasks to execute/ run on the manager or worker nodes. Service is the central structure of the swarm system and acts as the primary root for the user to interact with the swarm. When we create a service, we have to specify which container image to use and which commands to execute inside running containers. We have already discussed the services above in the working of Docker Swarm.
A task carries a Docker container as well as the commands to run inside this container. A task is the atomic scheduling unit of the swarm. Depending on the number of replicas set on the service scale, the manager node assigns tasks to worker nodes. Note that once a task gets assigned to a particular node, it cannot move to another node. It can run or fail on the assigned node only.
Load balancing
The swarm manager has the feature of ingress load balancing. Ingress load balancing exposes the services that are to be externally available to Swarm. The service can either be assigned automatically to a PublishedPort, or the swarm manager can configure any unused port as PublishedPort for the service. In case the port is not specified, the Swarm manager will assign the service to a port in the range 30000 - 32767.
One can access the service on the PublishedPort of any node in the cluster by external components. For example, cloud load balancers, irrespective of whether the node is currently running the task for the service or not. Note that all the nodes in the swarm route ingress connections to a running task instance. The Docker Swarm mode has an internal DNS component that automatically assigns a DNS entry to each service in the Swarm cluster. The Swarm manager then uses the internal load balancing to distribute the requests among services within the cluster based on the DNS name of the service.
Setting up Docker Swarm cluster.
Now let us set up a Docker Swarm manager node and a service on Ubuntu 16.04. The prerequisite for this setup is we should have the latest version of Docker Engine installed on the host. So let us begin with the steps.
1. Download and run the container.
First, we can verify the docker version on the host. Then we download the container, say MySQL using the following command.
docker pull mysql
This command will download the latest version MySQL container as shown in the output below.
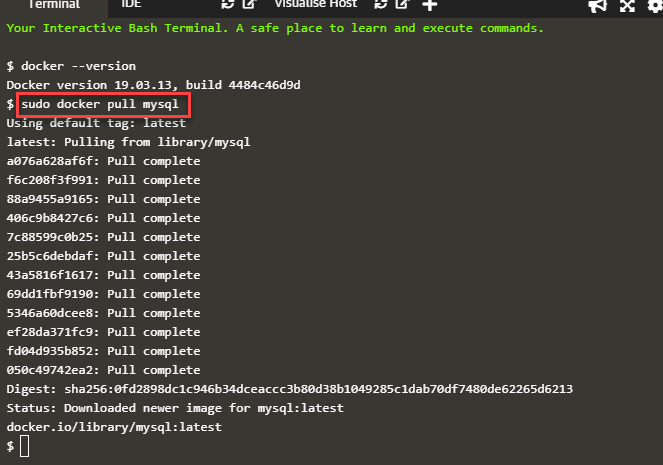
Next, we run this container using the following command.
docker run -d -p0.0.0.0:80:80 mysql:latest
This command generates the following output.
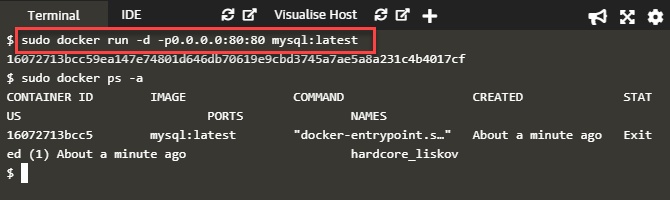
As seen in the above screenshot, we can verify the running of the MySQL container using the 'docker ps -a' command that shows an entry of the above container. Once the container is running now, we go ahead and create Docker Swarm.
2. Create Swarm - docker using swarm init command
Here first, we create a Swarm cluster by giving the IP address of the manager node. For this, issue the following command.
docker swarm init --advertise-addr 192.168.2.151
This command generates the following output.
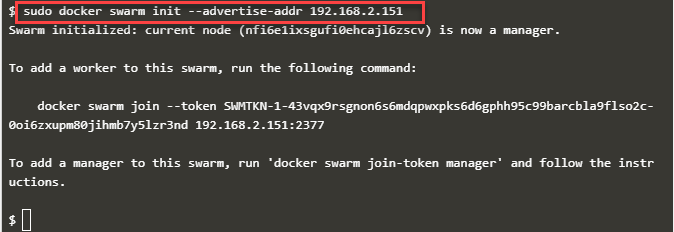
As you can see from the above output, the manager node created.
Note: We can similarly create a worker node by copying the command of the “swarm init” (above command) and pasting the output onto the worker node "sudo Docker Swarm join --token SWMTKN-1- xxxxx". It has to execute on a different host. So to create a complete swarm cluster, we require two hosts with the latest version of Docker Engine installed.
Once we do this, we proceed further and list the nodes from the manager node with the following command.
docker node ls
This command will generate the following output.
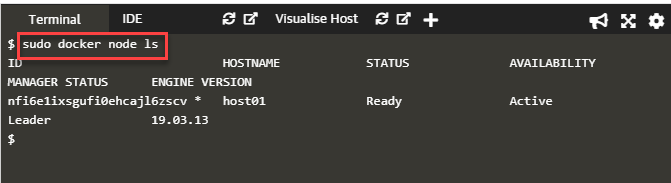
As of now, we have only the manager node, and hence the above command shows only the manager node details. Once we create a worker node, it will also show those details.
Next, we launch the service in Swarm mode. We have to do it in the manager node. We will deploy the simple service 'HelloWorld' using the following command.
docker service create --name HelloWorld alpine ping docker.com
The command generates the following output.
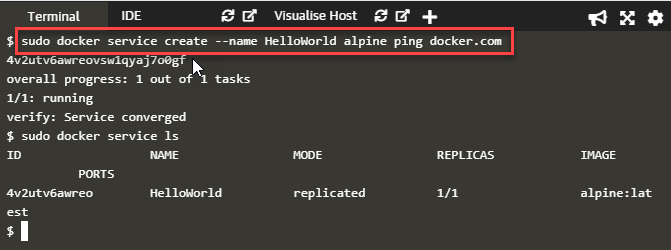
We can verify the service using the 'docker service ls' command as shown in the output above. This way, our swarm cluster on Ubuntu 16.04 is complete.
For a complete list of Docker Swarm commands, refer to Docker Swarm Commands.
Swarm Mode CLI commands
The following table shows the Swam mode CLI commands.
| CLI Command | Description | Command Usage |
|---|---|---|
| swarm init | This command initializes a swarm. The docker engine on which this command executes becomes a manager node. | docker swarm init [OPTIONS] |
| swarm join | It joins the swarm cluster as a node. Depending on the value of token passed (using –token flag), the node joins as a manager node or worker node | docker swarm join [OPTIONS] HOST:PORT |
| service create | The command creates a new service | docker service create [OPTIONS] IMAGE [COMMAND] [ARG...] |
| service inspect | The command “service inspect” displays detailed information about the specified service in a JSON array. | docker service inspect [OPTIONS] SERVICE [SERVICE...] |
| service ls | “service ls” command lists the services. | docker service ls [OPTIONS] |
| service rm | Remove one or more services from the swarm | docker service rm SERVICE [SERVICE...] |
| service scale | Using this command, we can scale up or down one or more services to the desired number. We can apply this command only to replicated services. | docker service scale SERVICE=REPLICAS [SERVICE=REPLICAS...] |
| service ps | Lists the running tasks that are part of the specified services. | docker service ps [OPTIONS] SERVICE [SERVICE...] |
| service update | Update the specified service | docker service update [OPTIONS] SERVICE |
Note: All the above commands work only for client and daemon API with version 1.24 and above.
Kubernetes vs. Docker Swarm
The below table shows the significant differences between Kubernetes and Docker Swarm.
| Kubernetes | Docker Swarm |
|---|---|
| Is complex. | A swarm is a simple tool. |
| We share the Kubernetes with containers in the same pod. | We can share the Docker Swarm with any container. |
| Kubernetes is quite difficult to set up. | Swarm is comparatively easy to set up. |
| We need manual load balancing in Kubernetes. | Swarm has automated load balancing. |
| In Kubernetes, deployment of containers and scaling are slower. | In Swarm, container deployment is much faster. |
| We should rewrite the YAML when switching platforms in Kubernetes. | In Swarm, we can easily deploy a container to different platforms. |
| Kubernetes contain built-in tools to manage both processes. | Swarm does not require tools for logging and monitoring. |
| It has a high availability among distributed nodes. | It has increased the availability of applications through redundancy. |
Key TakeAways
- The Docker Swarm is an orchestration tool. Additionally, it has two significant nodes, namely, the manager node and the worker node. The manager node is responsible for the management of the Swarm cluster and distributing tasks to worker nodes. Worker node checks for tasks and then completes them.
- In addition to the above, the worker node is associated with an agent that communicates with the manager node regarding the status of the task. Thus, helping the manager node to maintain the status. Moreover, we have also set up a Swarm cluster in the above article.
- Consequently, it completes the article discussing the brief overview of Docker Swarm.